蓋世汽車訊 有一天,人們可能希望自己的家用機器人把一大堆臟衣服搬到樓下,并把它們放進地下室最左邊角落的洗衣機。機器人需要將指令與它的視覺觀察結合起來,以確定它應該采取什么步驟來完成這項任務。
(圖片來源:arXiv)
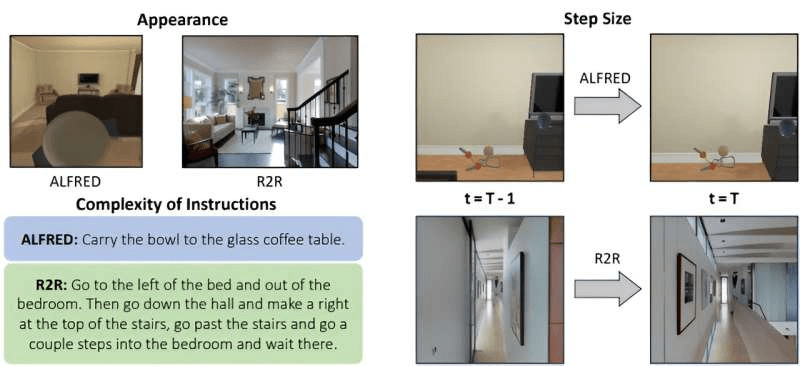
對于人工智能本體(AI agent)來說,這說起來容易做起來難。當前方法通常使用多個人工創建的機器學習模型來處理各部分任務,基于大量的人力和專業知識而構建。這些方法通過視覺表征(visual representation)來直接做出導航決策,需要大量的視覺數據來進行訓練,而這些數據通常很難獲得。
據外媒報道,為了克服這些挑戰,麻省理工學院(MIT)和MIT-IBM Watson AI實驗室的研究人員設計了一種導航方法,將視覺表征轉換為語言片段,然后將其輸入大語言模型中,該模型可以實現多步導航任務中的所有部分。
來源:第一電動網
作者:蓋世汽車
本文地址:http://m.155ck.com/news/shichang/234238
以上內容轉載自蓋世汽車,目的在于傳播更多信息,如有侵僅請聯系admin#d1ev.com(#替換成@)刪除,轉載內容并不代表第一電動網(m.155ck.com)立場。
文中圖片源自互聯網,如有侵權請聯系admin#d1ev.com(#替換成@)刪除。




先估價再買車,買的放心開的安心
您的詢價信息
已經成功提交我們稍后會聯系您進行報價!

 京公網安備
11010502033163號
京公網安備
11010502033163號