關(guān)注并標星電動星球News
每天打卡閱讀
更深刻理解汽車產(chǎn)業(yè)變革
————————
出品:電動星球 News
作者:毓肥
上周五,特斯拉正式揭開了 DOJO 的神秘面紗。
在當時的首發(fā)文章里面,我們重點回顧了整場發(fā)布會的主要內(nèi)容。由于 AI Day 的主角太多,所以 DOJO 有關(guān)的部分,我們在保證閱讀體驗的基礎(chǔ)上,更多地只能講療效。

但如果不能跟大家交流更多 DOJO 的信息,我們覺得 AI Day 白看了。
因為這場發(fā)布會是特斯拉正式轉(zhuǎn)型,或者說正式成為人工智能公司的節(jié)點。而 DOJO 則是這家人工智能公司最底層,也是最重要的硬件產(chǎn)品。
但到底應(yīng)該怎么理解 DOJO,怎樣用更易懂的語言讓大家看到特斯拉的巧思、創(chuàng)新,甚至是狂想?
最終我們決定,把這臺 1.1EFLOPS 算力的 DOJO Pod,當成一個「人」:
那么作為「細胞」存在的,應(yīng)該是特斯拉自研的人工智能訓練「節(jié)點」;
作為「器官」存在的,則是 354 個節(jié)點構(gòu)成的 D1 芯片;
而 25 個 D1 芯片組成的「Training Tile」,又構(gòu)成了 DOJO Pod 的「功能系統(tǒng)」;
最終 120 個 Tile 組成的 DOJO Pod,則是一個完整的超算。
也就是說,特斯拉從細胞級別的地基開始,完整地構(gòu)建了一整套超算系統(tǒng)的大廈。除了英偉達和谷歌,目前還沒有哪家科技企業(yè)展現(xiàn)過這樣的能力,更不用說車企。
今天的開頭有點長,因為我們希望盡量寫一篇更多朋友能理解的文章,而不是簡單地堆砌術(shù)語。
接下來,我們就從最基本的單位開始,帶大家在 DOJO Pod 里面走一遍。
一、DOJO 的細胞
特斯拉將 DOJO 的最小組成單位,命名為「Training Node」,訓練節(jié)點。它是 DOJO 的細胞,更是特斯拉芯片哲學的最精簡具現(xiàn)。

每一塊 D1 芯片里面擁有354 個這樣的節(jié)點,我們可以近似地將它理解為「核心」。也就是說,每一塊 D1 可以近似理解成 354 核的芯片。但這個「核」與我們談?wù)撟约译娔X酷睿 i5、i7 時的「四核」、「八核」依然有明顯的區(qū)別。
1. 所以,「Training Node」究竟是個啥?
6 月底出席 2021 CVPR 會議時,特斯拉 AI 部門主管 Andrej 表示,一共有 5760 個英偉達 A100 GPU,為特斯拉的深度學習網(wǎng)絡(luò)服務(wù)。
CPU 和 GPU,可能是我們接觸最多的芯片名詞,而一般來講,GPU 比 CPU 更適合用于深度計算。

為什么 GPU 更適合?因為從結(jié)構(gòu)上來說,GPU 更適合大規(guī)模、低精度的運算,CPU 更適合小規(guī)模(相對小)、高精度運算。
我們決定不去解釋 CPU 和 GPU 之間的結(jié)構(gòu)差別,因為一個比喻就能搞定:CPU 是幾位大學教授研究數(shù)論,GPU 是幾百位中學生算一元二次方程。
于是問題就變得更容易理解了:為什么中學生比大學教授更適合深度學習?
因為深度學習的本質(zhì),就是低精度+大規(guī)模的卷積運算。對于神經(jīng)網(wǎng)絡(luò)運算,「核心規(guī)模」比「單個核心的精度」權(quán)重更高。
說得再簡單一點,就是讓 10 位數(shù)學教授算 10 萬條一元方程,一定沒有 1 萬個中學生算得快。
所以,特斯拉需要把自家的人工智能芯片設(shè)計成類 GPU 架構(gòu),也就是單個核心無須特別復(fù)雜,但核心數(shù)要多。
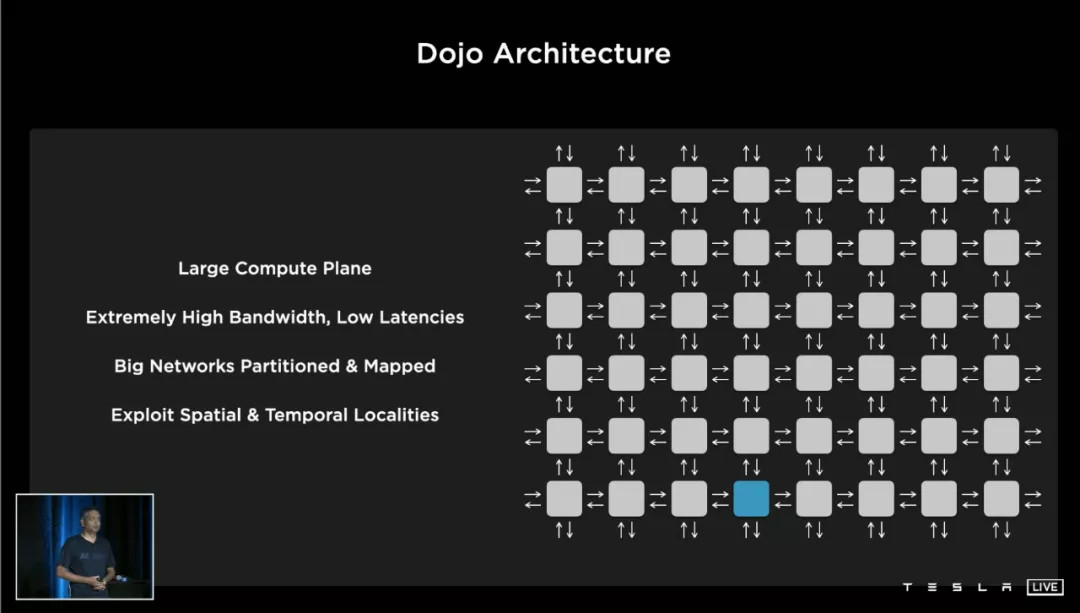
「Training Node」,就是一種接近 GPU 核心結(jié)構(gòu)的產(chǎn)物,但由于它對特斯拉自己的算法高度優(yōu)化,所以比英偉達賣的萬能鑰匙 GPU 稍微復(fù)雜;但它又要比純粹的 CPU 更適合深度學習,所以規(guī)模更大。
2. 造細胞的世界觀有了,方法論呢?
從這一小節(jié)開始,有一個詞語希望大家牢記:帶寬 Bandwidth。
AI Day 的首發(fā)文章里,我們提到過算力并不是特斯拉的核心訴求。
一塊芯片的算力來源于半導體工藝,而特斯拉只負責選擇工藝(甲方),不負責生產(chǎn)(乙方,臺積電);只要特斯拉有錢買目前最先進的工藝,臺積電一定可以把晶體管給你堆得滿滿當當。
但如何將芯片設(shè)計得完美符合需求,也就是如何安排晶體管,這是砸錢無法解決的,也是真正衡量一家芯片公司技術(shù)實力的天平。
特斯拉的 AI 硬件方法論很簡單:一切為帶寬服務(wù)。
進入 AI 時代,所有標榜 AI 性能的芯片廠商,都在追求帶寬最大化。比如英偉達為自家 A100 芯片配備了 HBM 超高帶寬顯存,并且通過高帶寬橋接器 NV-Link 連接多個 A100。這也是特斯拉在 DOJO 正式使用之前選擇英偉達的重要原因。
為什么深度學習需要海量帶寬?
再來一個不算準確,但足夠形象的比喻:寫下 10 條大學向量代數(shù)習題需要的紙,一定比寫 1 萬條一元二次方程需要的紙少。深度學習需要的是大規(guī)模低精度運算,產(chǎn)生的低精度數(shù)據(jù)量非常可觀。
目前 AI 界硬件公司的思路是帶寬開源,而軟件公司的方向則是算法節(jié)流。至于算力,本質(zhì)上歸半導體代工廠管。
3. 所以如何從最基礎(chǔ)的部分開始,最大化 DOJO 的帶寬?

這塊東西我們下面會詳細說,叫做 Training Tile。之所以提上來,是需要解釋一個概念——Tile 這個單詞用于芯片領(lǐng)域,并不是特斯拉的首創(chuàng),它起源于 1997 年的麻省理工。
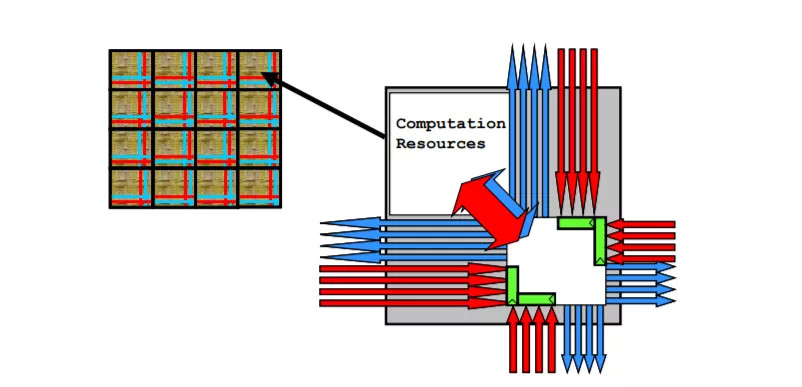
上面的芯片結(jié)構(gòu)圖叫做 RAW,基于麻省理工 1997 年的一篇論文首次提及的「劃分方式」打造,這種方式就叫做 Tile。
Tile 的特點,是它把處理單元、SRAM 緩存、網(wǎng)絡(luò)接口等等模塊集成在一個區(qū)域內(nèi),不同的區(qū)域之間通過 NoC,network on chip(片上網(wǎng)絡(luò))互連。它不像是一種架構(gòu),而更像一種排列方式。
這種排列方式的好處,是擴展能力更強(比如堆疊更多核心)、核心之間連接方式多樣且迅速。
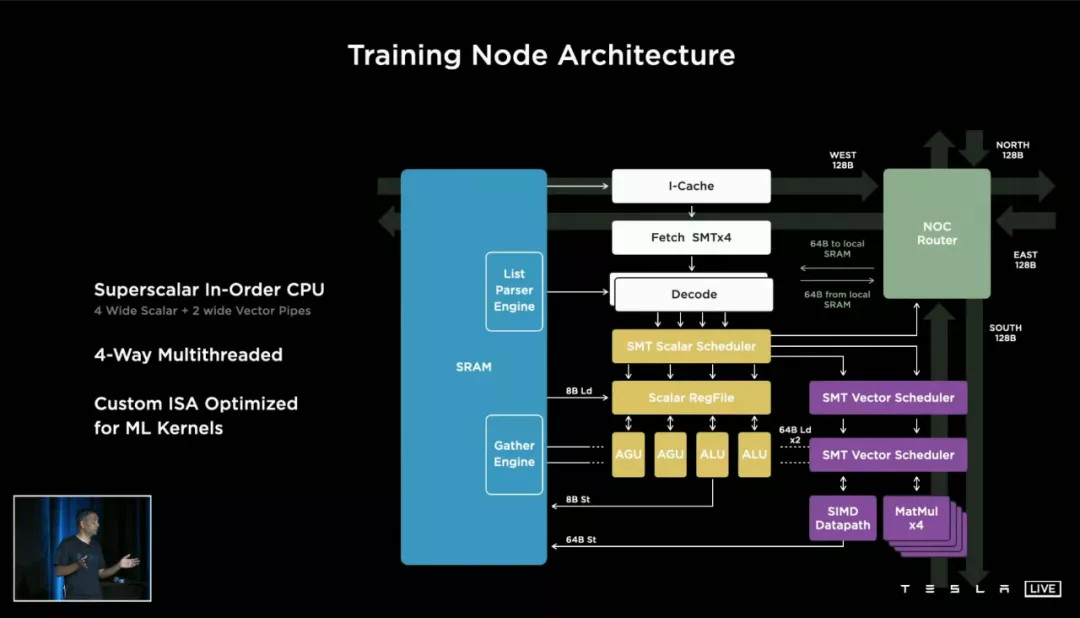
回到特斯拉的 Training Node 結(jié)構(gòu)圖。負責計算的單元并不是本文討論的重點,右上角這一塊「NoC Router 片上網(wǎng)絡(luò)路由器」,才是 Training Node 的精髓。
特斯拉為每一個 Node 設(shè)計了東南西北(上下左右)各 64bit 的片上NoC通道,這使得 Node 之間核心堆疊和數(shù)據(jù)傳輸?shù)碾y度大大降低——或者打個比喻,堆樂高的時候你發(fā)現(xiàn)每一塊積木都能從上下左右往外砌。
內(nèi)核間多方向的片上 NoC 通道,其實是 AI 芯片的共同趨勢。像是此前拿下單芯片面積之最的 Cerebras WSE,其內(nèi)部同樣使用了 NoC 片上網(wǎng)絡(luò)通信。
二、D1 芯片
聊到這里,我們沖出了 Training Node,來到了芯片層面。
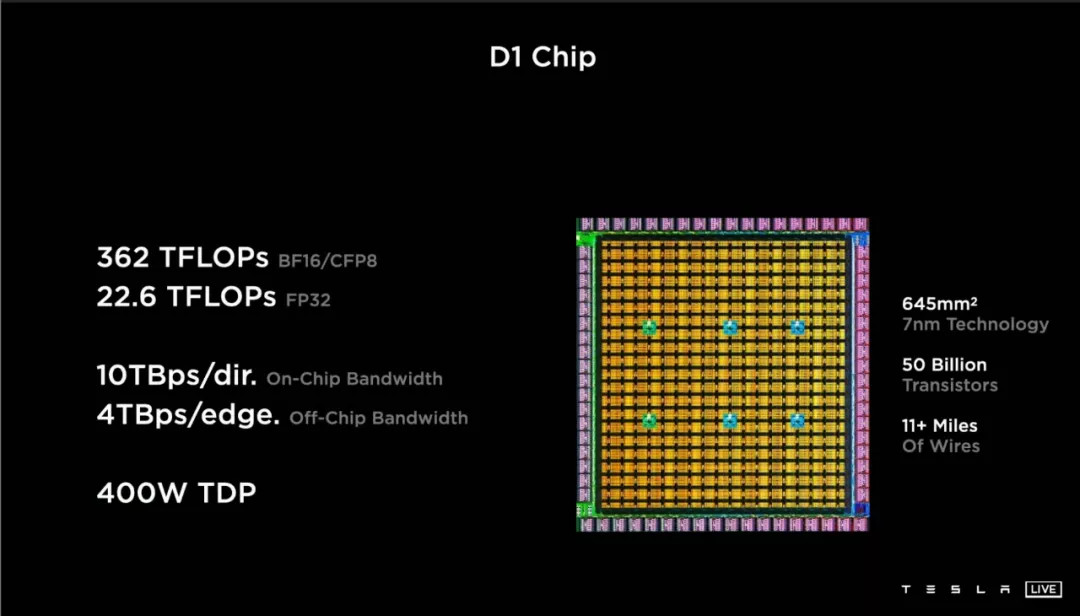
28 個月之后,特斯拉重拾自己芯片設(shè)計公司的頭銜,帶來了第二款自主設(shè)計的芯片產(chǎn)品。
和 2019 年在車規(guī)級的籠子里跳舞不一樣,這次的 D1 芯片是數(shù)據(jù)中心級別的產(chǎn)品——這意味著特斯拉終于可以毫無顧忌放肆一把。
這枚 D1 芯片的基本參數(shù)是:645 平方毫米面積、500 億個晶體管、11 英里的內(nèi)部走線、400W TDP(Thermal Design Power 熱設(shè)計功耗,指正常工作環(huán)境的負載功耗)。
首先要說的,是 D1 晶體管密度非常高,每平方毫米晶體管數(shù)量達到了 7752 萬個,這已經(jīng)打平了使用臺積電二代 7 納米工藝的蘋果 A13,超越了初代臺積電 7 納米工藝打造的英偉達 A100。
臺積電的功勞就說到這,接下來講特斯拉做了什么。
1. 10TB 每秒的on-chip bandwidth 片上帶寬,這是極其恐怖的數(shù)字。
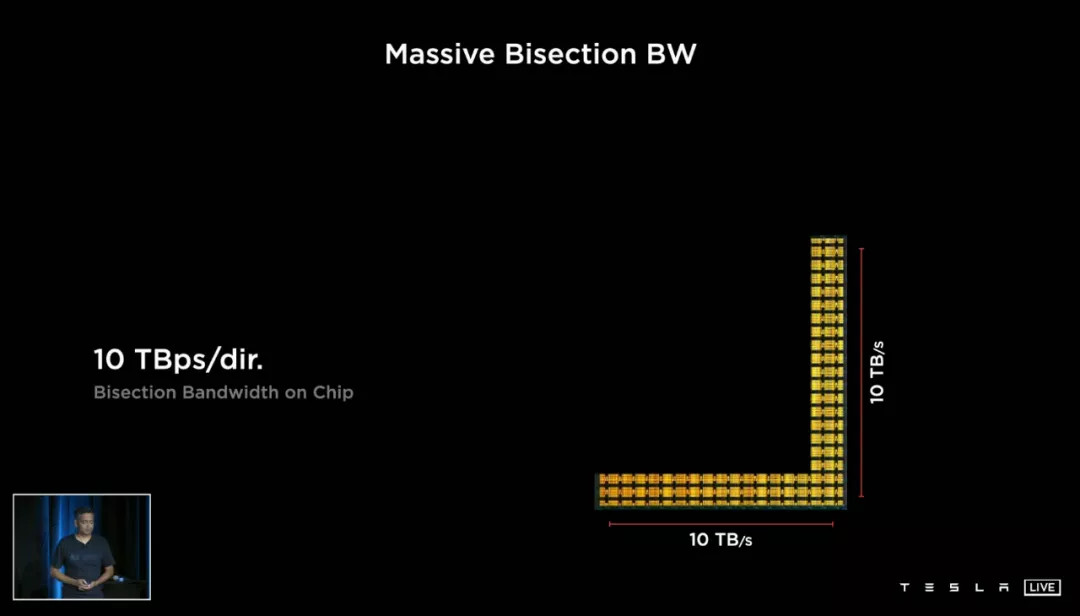
沒有對比就沒有傷害,2019 年同樣標榜自己 on-chip 帶寬業(yè)內(nèi)頂尖的英特爾 Stratix 10MX(一款最高擁有 10TOPS FP32 精度算力的通用計算芯片),這個指標為 1TB 每秒。
但這里 10TB 指的更像是最理想結(jié)果,D1 芯片每個 node 每個方向的帶寬是 512GB,10TB 指的是每一行(列)node 同時傳輸數(shù)據(jù)時達到的最大帶寬。
2. 另一個指標是 4TB 每秒的 off-chip bandwidth 片外帶寬。
這里涉及到另一個名詞:SerDes,全稱 Serializer-Deserializer,序列化器與反序列化器。
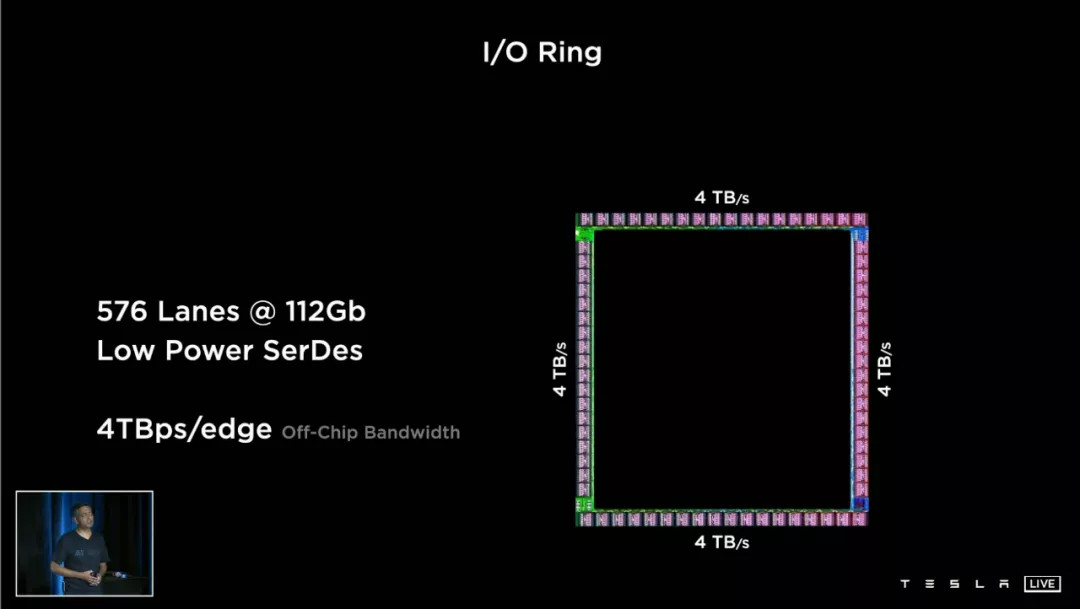
我們還是只講療效:SerDes 是一種同等體積下增加帶寬、減少信號數(shù)量的工具,可以降低芯片功耗和封裝成本。
目前單一 SerDes 接口最快的傳輸速率達到了 112Gbps——而特斯拉在每一塊 D1 芯片的四條邊上,都累計布置了 576 個 112Gb 帶寬的 SerDes 接口。
4TB 每秒到底有多快?特斯拉用了一張 PPT 作對比:
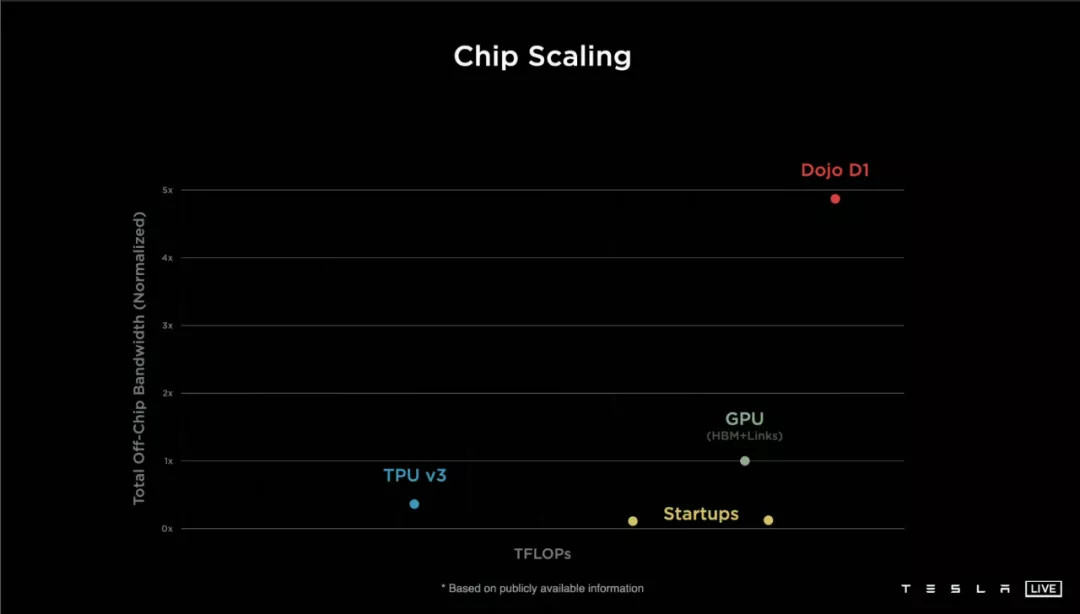
不過有些「營銷術(shù)語」我們得挑出來,比如用作對比的谷歌 TPU V3 已經(jīng)是 2018 年的老產(chǎn)品,3 個月前 TPU V4 登場,各項指標并不比 D1 差。
三、Training Tile
下圖所示,就是組成 DOJO Pod 的基本單元。

每一塊 Tile 上面都封裝著 25 塊 D1 芯片,總算力高達 9PFLOPS,芯片四周擴散出每邊 9TB 每秒的超高速通信接口,然后上下則分別連接著水冷散熱,以及供電模塊。
到這里,DOJO 的超高帶寬系統(tǒng)已經(jīng)完整呈現(xiàn):
D1 芯片內(nèi)上下左右各 10TB 每秒→D1芯片間上下左右各 4TB 每秒→5x5 D1 芯片方陣各邊 9TB 每秒→Tile 與 Tile 之間最高 36TB 每秒。
一個 GB 級別的「小」數(shù)字都沒有。

為了實現(xiàn)這些數(shù)字,特斯拉最終設(shè)計了「可能是芯片工業(yè)史上最大的 MCM 封裝」——這是特斯拉 Autopilot 硬件高級主管 Ganesh Venkataramanan 的原話。
但特斯拉的工程魔法還沒結(jié)束。

上面是谷歌 TPU V3 的散熱示意圖。一塊主板上四枚TPU用一個共同的水路散熱。到了 TPU V4,水冷系統(tǒng)變得復(fù)雜,效率也提升了:

但這種冷卻系統(tǒng)有一個弊端:無法兼顧供電元件,需要另外考慮供電部分的散熱。
一個 DOJO Tile 上面有 25 塊 D1 芯片,最保守估計功耗也超過了 10kW,120 個 Tile 功耗相當于一個 10 樁 V2 超充站火力全開——超充站的變壓器也是需要散熱的。
特斯拉的解決方案有點像電腦領(lǐng)域的「分體水冷主板」:用垂直水路將芯片、供電元件連接起來,用最少的水路搞定多個散熱需求。
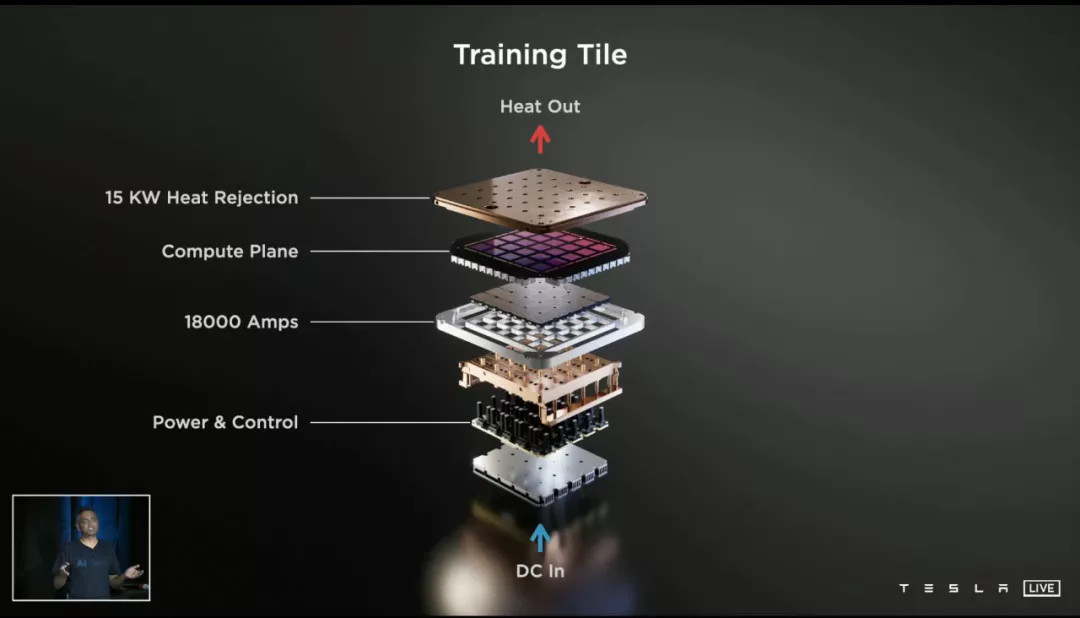
根據(jù) AI Day 的 PPT,每一塊 Tile 都配備了高達 15kW 散熱能力的水冷系統(tǒng),但最終結(jié)構(gòu)卻簡單得過分:

四、DOJO Pod
120 個 Tile 組成的 Pod,是 DOJO 的最終形態(tài)。1.1Exaflops,則是一個 DOJO Pod 的最高算力。
Pod 在這個語境下,指的是「通過網(wǎng)絡(luò)手段連接在一起的多臺計算機」,但一個 Pod 可以做到多大,業(yè)內(nèi)沒有明確規(guī)定。

但這里要強調(diào)一下,1.1E 算力并非在超算界用的 FP32 完整精度測得,而是 BF16/CFP8 精度。
BF16 精度,又叫 BrainFloat16,是為深度學習而優(yōu)化的新數(shù)字格式,它保證了計算能力和計算量的節(jié)省,而預(yù)測精度的降低幅度最小,目前支持 BF16 精度的,已經(jīng)有英特爾、谷歌、ARM 等等巨頭。而 CFP8 則是特斯拉自優(yōu)化的精度。
「節(jié)省」是什么意思?舉個例子,FP32 精度就是你告訴別人「我在廣州市天河區(qū)天河路 218 號天環(huán)廣場地上一層 L128 號商鋪」,而 BF16 就是你告訴別人「我在廣州天環(huán)廣場」。
那么如果計算 FP32 精度,DOJO Pod 是個怎樣的水平?
單個 D1 芯片可以達到 22.6T 的 FP32算力,那么整個 Pod 理論上就是 22.6x25x120=67800TFLOPS 的 FP32 算力。
現(xiàn)在我們看看 2021 年上半年的 HPC 全球超算 TOP500 排行榜:
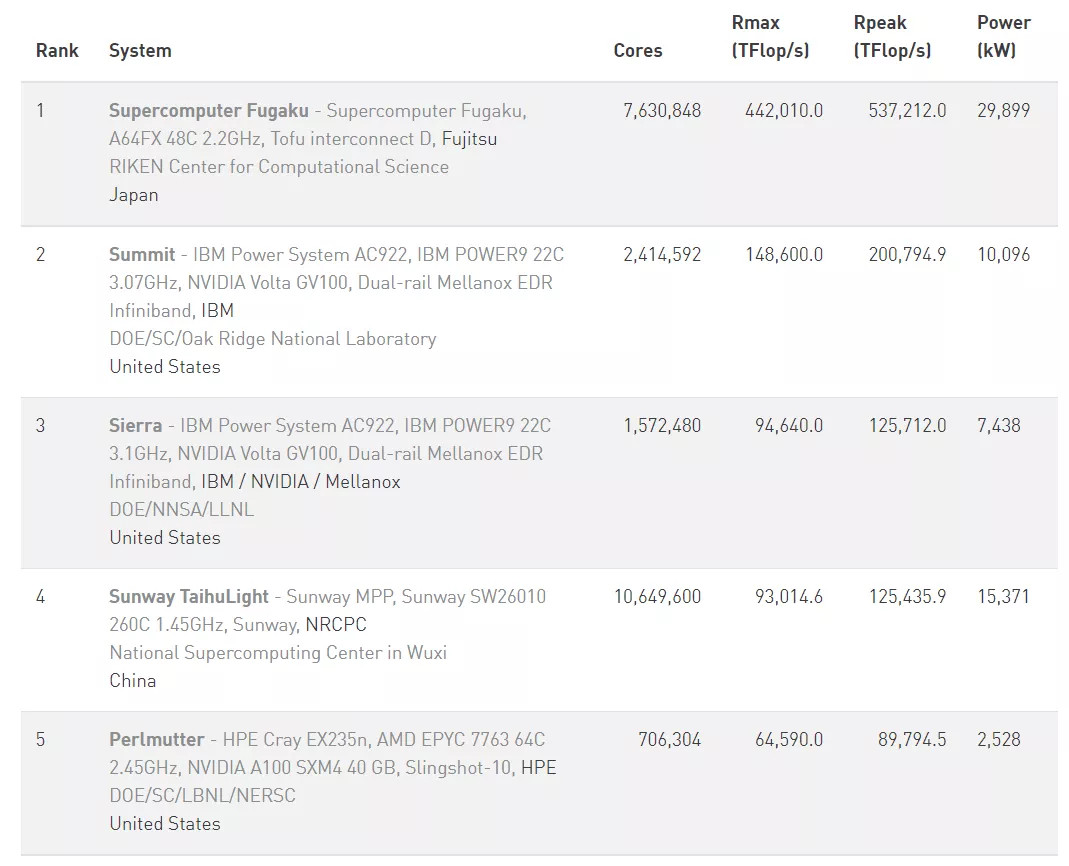
67800TFLOPS 的算力可以排在第五位(看 Rmax 算力那一列),剛好把曾經(jīng)的「全球最強 AI 計算機」,服役于美國國家能源研究科學計算中心(NERSC)的 Perlmutter擠掉。

但達到這個成績,特斯拉只用了一個 Pod(機柜),而 Perlmutter有 4 個長機柜。
最后
文章到這里就寫完了。
非常慶幸我能在 4000 字以內(nèi),將最希望與大家分享的 DOJO 相關(guān)細節(jié)寫完,并且盡自己的能力,把術(shù)語解釋得稍微淺顯一點。
但對于特斯拉來說,它作為一家人工智能企業(yè)的生涯,也許才剛剛開始。
馬斯克在 AI Day 上面說「特斯拉其實也是全球最大的機器人生產(chǎn)公司,我們生產(chǎn)的是輪上機器人」。然后他帶來了真正的特斯拉機器人,并且明年就會有原型了。
無論是智能電動汽車,還是人工智能,都還處于雛形階段。特斯拉、谷歌,或者國內(nèi)的新造車「御三家」、華為、百度,它們更像是「探索者」,而不是「收獲者」。
也正因為人類下一輪生產(chǎn)力大解放還處在黎明前,我們才能看到趨勢,預(yù)測變化,并且親眼見證變革。
DOJO 不會是特斯拉的終點,也不會是人工智能的終點,但多年之后回過頭來,它也許會是個「預(yù)兆」,或者說「開篇」。
(完)
來源:第一電動網(wǎng)
作者:電動星球News蟹老板
本文地址:http://m.155ck.com/kol/154651
文中圖片源自互聯(lián)網(wǎng),如有侵權(quán)請聯(lián)系admin#d1ev.com(#替換成@)刪除。




先估價再買車,買的放心開的安心
您的詢價信息
已經(jīng)成功提交我們稍后會聯(lián)系您進行報價!

大牛說專欄作者")






 京公網(wǎng)安備
11010502033163號
京公網(wǎng)安備
11010502033163號