講述 | 郭繼舜
編輯 | HiEV

編者注:
本文是HiEV出品的系列直播「硬核拆解BEV」第一期,均勝電子副總裁郭繼舜分享的內容梳理。
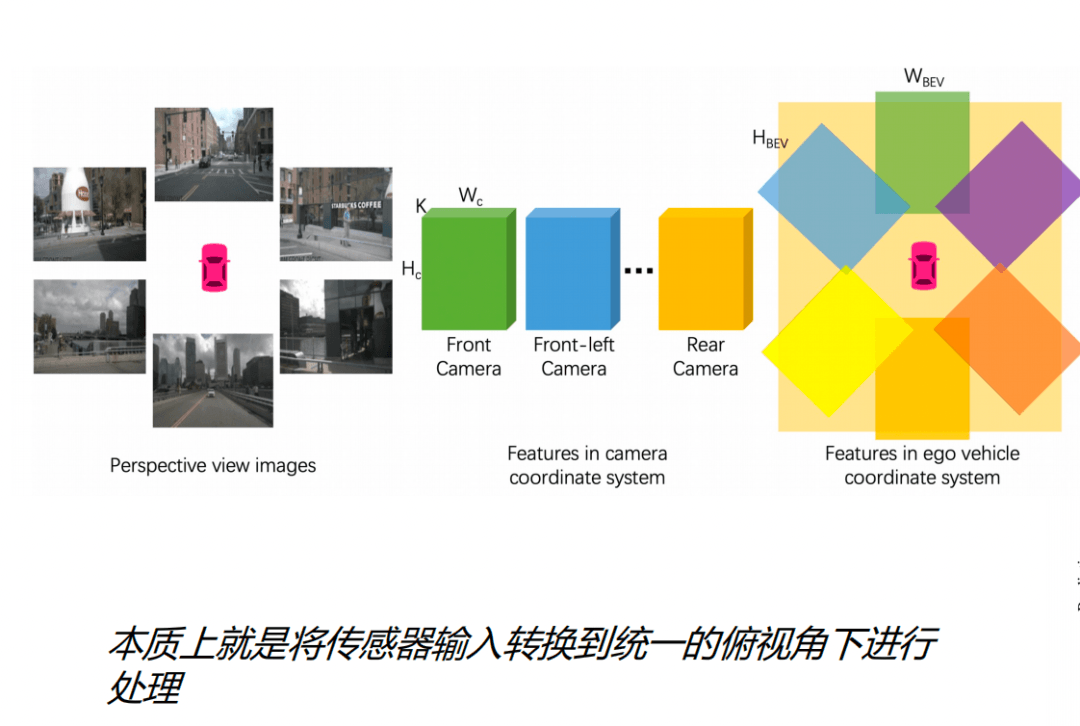
BEV全稱是Bird's Eye View(鳥瞰視角),實現方法是把原本攝像頭2D的視角通過算法校正和改變,形成基于上帝視角的俯視圖。
從本質上來說,BEV算法就是 將傳感器輸入轉換到統一的俯視角度下進行處理。
這里的傳感器不只有攝像頭,還有4D毫米波雷達、激光雷達等,算法把它們的信號融合,最終形成一個上帝視角。在計算機里面處理這部分信息時,也會基于上帝視角去進行規劃決策和控制。
首先是城市NOA的落地。
高速場景下L2++場景相對單一,感知任務不重,但控制方面很難,因為高速公路一般速度在80-120公里/小時,所以在高速場景下,如何把規劃決策和控制做好,保證它不會在邊界狀態下失穩就顯得尤為重要。
但是在城市道路上,它的 難點就在于感知,因為有非常多的交通參與者或者非常復雜的路況。
目前主要的城市NOA玩家:
原來做L4的科技公司:從Robotaxi上遷移感知,調整傳感器;
傳統Tier1或者OEM:把感知做好,處理好復雜場景。
在實現L2++功能時,大多希望360度范圍內能夠做到精確感知,需要做到傳感器融合,難度加大,復雜度增強,因此BEV愈發重要。
安信證券報告顯示,蔚小理等車廠通過OTA升級釋放城市NGP或者NOA功能的時間節點都在2022年到2023年之間。
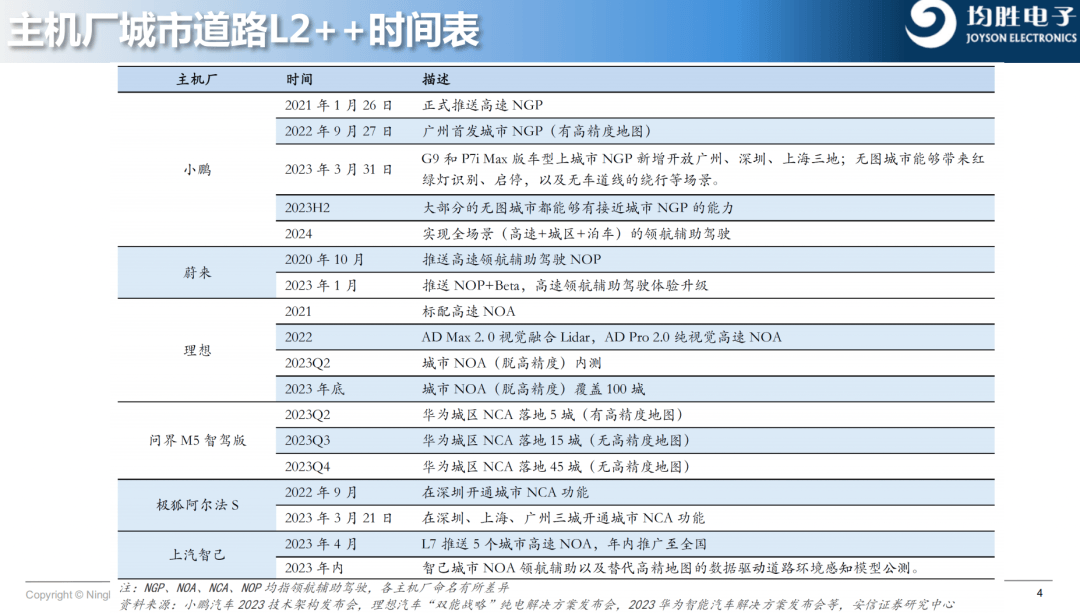
所以這就是為什么國內高速NOA對BEV的使用并不多,但隨著2021年特斯拉提出BEV算法,以及與transformer結合后,國內也開始在城市道路上去使用BEV算法解決復雜和不確定的城市道路場景。
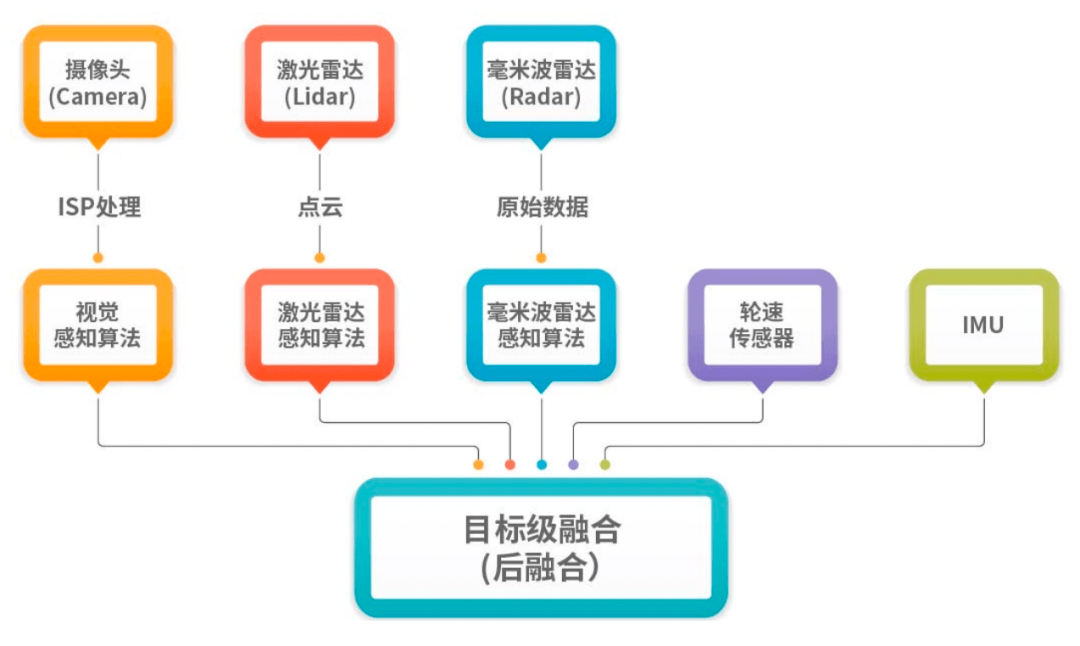
現階段量產里廣泛使用的后融合:
不同傳感器各自算各的,把感知和分類的結果做投票,這個投票是根據場景的不同計算權重的;
算法由不同供應商提供,不需要域上的大算力,但每個傳感器都可能丟失重要信息,比如高速公路上的破碎輪胎;
在行泊一體之前,大多數的行車、泊車是兩套完全不同的傳感器。
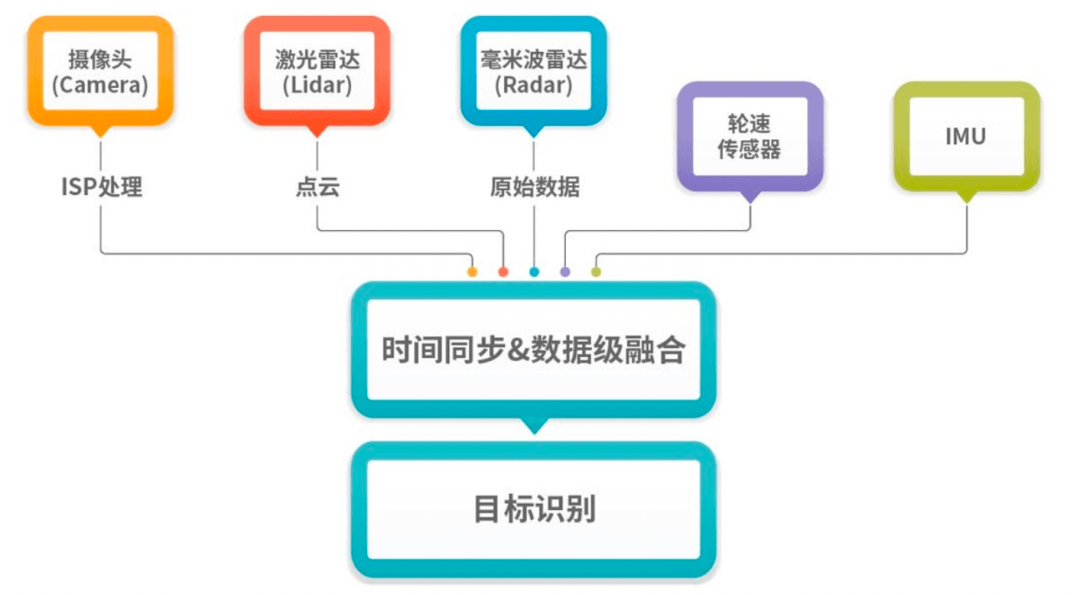
但是不同的后融合方案存在各種缺點,因此大家開始想辦法就開始去做 前融合:
前融合的就是嘗試把攝像頭上的像素,激光雷達的點云,毫米波雷達擬合過的一些特征信息(現在如果用4D毫米就是4D毫米波的點云,它已經能夠成像了),把這些信息去做原始數據的時空同步,然后再結合其他的信息,最后得到了一個多維度的Raw Data,再去做分類識別跟蹤等等。
但是這個過程中像素級的前融合非常難做,原因在于:
這么多點云與像素去做匹配的時候,時空同步難度很大;
算力消耗非常大;
不同的傳感器硬件系統時間是不一樣的,很難知道激光雷達的某一幀到底實際嚴格意義上對應了攝像頭或者毫米波雷達的哪一幀,而且存在運動補償的誤差。
即使做了非常詳細的標定,一旦換硬件或者換車型很多流程又要重新來一遍,所以我們在BEV里面開始去嘗試把這個問題得到系統性的解決,那到底是怎么解決的呢?
首先在BEV算法里面是用特征級的融合,然后再把它映射到統一的坐標下,即BEV的坐標體系里面。
然后去做融合,融合之后再進行訓練學習分類,最終后融合的特征可以保留,那么同時它又不像是前融合階段要求高精度和高算力,所以它是一個相對折中的一種方法。
這個方法我們叫 特征級的前融合,或者把它叫做 中融合也可以。
特斯拉AI Day曾展示一張圖:不同的攝像頭都對于這個特征做識別,后融合方面就是先把它做分割之后再去融合,最終得到的結果是基于BEV做特征級融合的效果,遠遠好于在BEV空間里面做的后融合,所以說特征級的融合能更好地解決后融合信息丟失過多而造成的誤差,同時也避免了像素級的融合,算力的災難和復雜度的災難。

BEV不是一個新的概念,深度學習賦予它活力,使用深度學習算法實現了從2D到BEV視角的轉換。
BEV除了加了深度學習之外,在2021年的時候,特斯拉還提出了大模型 transformer再加BEV的模型。
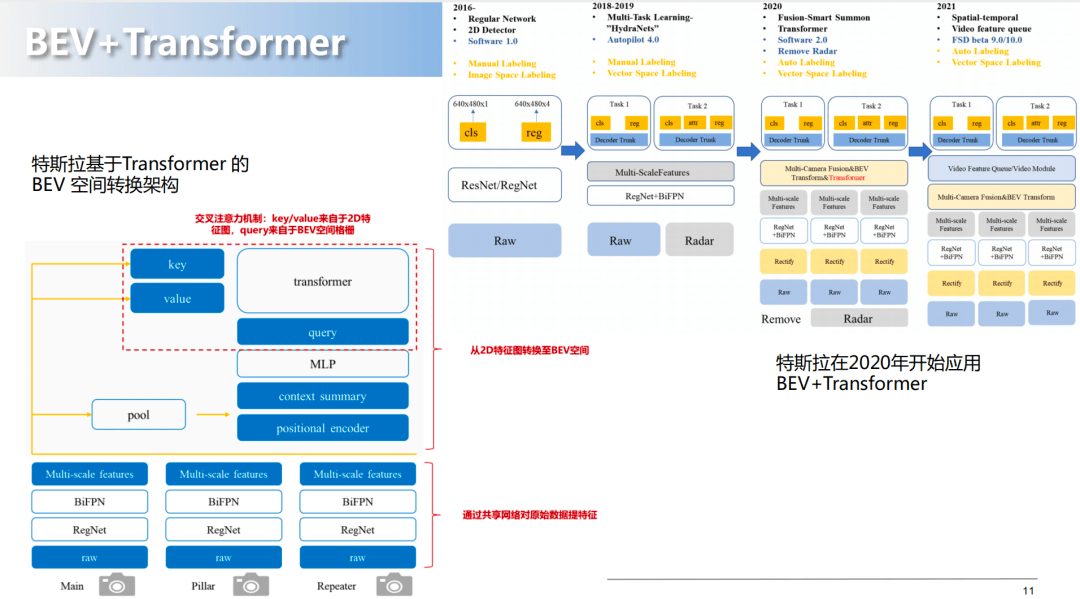
transformer作用是什么?就是給這些按照時間序列進入的特征和信息賦予權重。transformer最大的功勞就是,對于 特征給予或異構的特征,比如說同構的特征給予了注意力的新參數。
基于transformer的BEV算法優勢:
增加了系統的跟蹤和推斷的能力;
加了異構傳感器的融合和算法泛化能力;
實現了不同視角下在BEV中進行統一的表達;
對于端到端的優化,模塊更簡潔了,任務的可擴展性也更強了。
擁有構建語義地圖的能力,即是方案可以擺脫高精地圖。
在2021年特斯拉在提出 BEV之前,我曾經是高精地圖堅定的支持者,但最后發現高精地圖的更新成本等因素導致它的局限性,尤其是如果要做自動駕駛方案出海,還要涉及不同國家的高精地圖。
之后,各大車廠陸續開始通過 BEV算法和得到的信息構建語義地圖,非常典型的應用就是有些車廠提出來的 高頻路線的城市道路NOA。
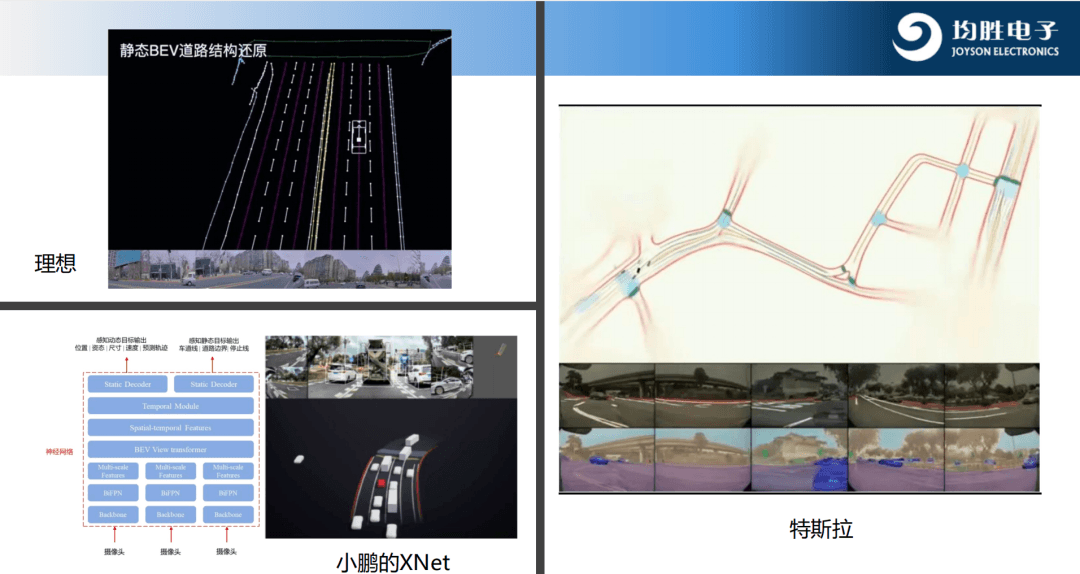
特斯拉通過BEV算法加transformer去構建一個城市道路下高級別智能駕駛所需的語義地圖,但是這個過程的實現需要結構化訓練數據來源,要基于BEV的模型去做數據的標注、分割、分類等等。
那么要標多少數據?
毫末智行CEO顧維灝預測,BEV的模型 大概要標注1億公里的數據,所以這個量是非常大的。因此特斯拉就推出了自動標注,怎么做自動標注?
在影子模式的過程中得到了非常多的數據,數據能夠自動地進行相對準確的標注;
然后用人工進行抽檢的方式,能夠現在越來越好地為深度學習/transformer的模型等提供更多輸入數據。
這樣一方面是有影子模式去收集場景數據。另一方面又通過自動標注把這些數據變得結構化。通過這樣的方式打通,就使得特斯拉成為了全世界到現在為止獲取相對準確的結構化信息數據的最快也最廉價的一個車企。
除此之外,特斯拉在AI Day透露,另外一個數據來源就是 虛擬仿真。
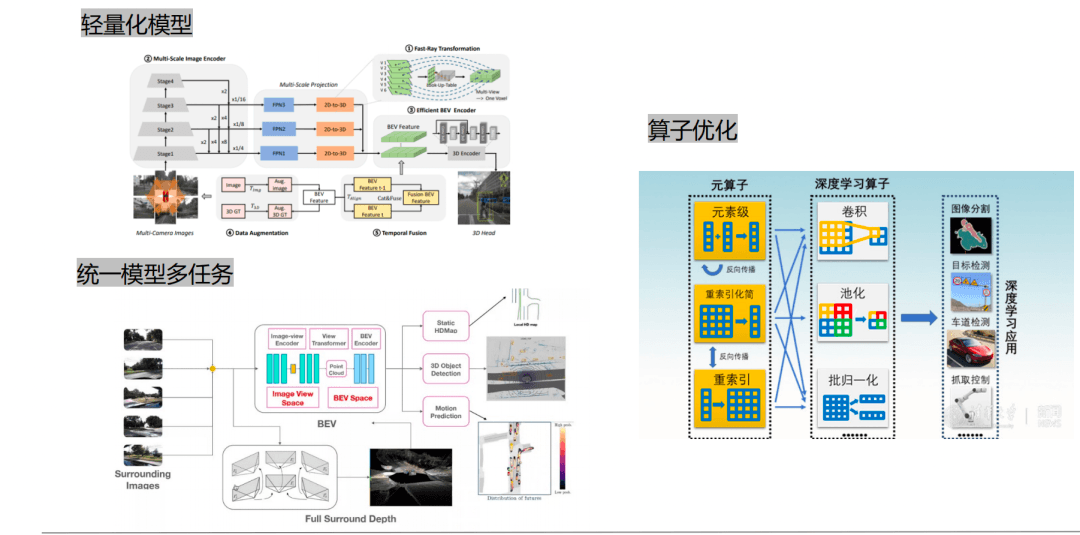
除了對數據要求比較多,BEV算法對算力的要求也比極高。那BEV算法如何才能降低算計的消耗呢?
用相對輕量化的模型;
用多任務模型就統一一個模型,但輸出多個任務可能是靜態可能動態的,反正就是用一個模型輸出多個;
對算子做一些優化。
占用網絡依然是一個類似于“上帝視角”的視角,還把多個傳感器做了融合。
下方圖像是特斯拉的結果,他們把空間做了網格化的分區,分割之后,每一個小方塊叫做體素,類似于像素。
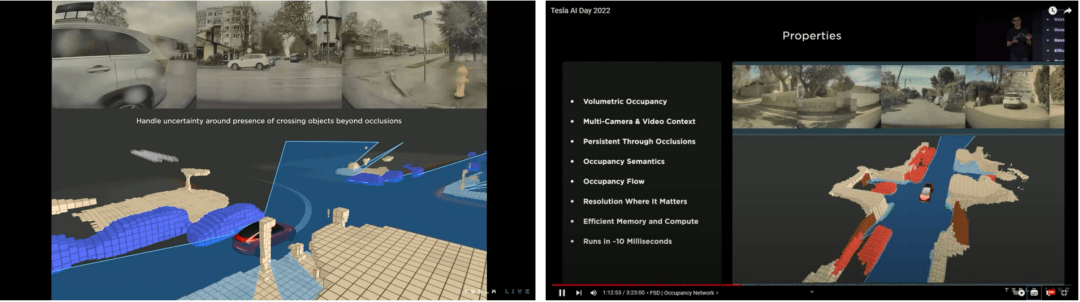
只要在這個空間的體素下被占用了,都會被系統認為是1,賦值1,否則賦值為0。只要知道物體在空間里面占據了一定的體素,系統就會把它顯示出來,并判定它是一個障礙物。
特斯拉的想法是,應用好占用網絡,再加上4D雷達點云信息去做融合,解決了部分特殊場景問題后,最終就能取代激光雷達。
在2020、2021年前后, 元戎啟行的CEO周光也曾向我展示過類似于體素的概念,這可以說明我們國內的科技公司對這部分技術掌握得很不錯。
占有網絡解決了不識別就不能作為障礙物的問題,后續我們還需要對相關算法繼續做更多的優化,去減少算力的消耗,同時增加它的實時性,才能保證獲取有更好的效果。
Q:如果高精地圖后續大規模開放,各家會繼續走輕地圖重感知的路線還是重新去用高精地圖?
A:高精地圖的更新成本巨大,且更新頻率低,而隨著感知算法效率的提升,系統對高精地圖的依賴性將逐步降低。
Q:大概在兩三個月以前,李想表示要轉向BEV加transformer的方案,理想汽車要在2030年成為一家AI公司。從這么一個角度來看, BEV加transformer的方案它到底是有學術意義上的貢獻,還是說它其實解決了一些工程上問題?
A:transformer本身是一個創新性、顛覆性的東西,但是transformer和BEV的結合,或者說比如深度學習和BEV的結合,這是由工程驅動的解決問題的方式所得到的創新。
Q:BEV加transformer的方案對整個軟件或者算法層面的架構,從整個硬件的計算架構來說,它會產生怎樣的一些影響?
A:在軟件層面,剛開始大家會基于BEV整理一套架構。比如說,很多的科技公司開始去提出基于BEV去做各種傳感器的訓練,然后得到了一個BEV平臺,之后可以在上面去適配更多不同像素的攝像頭、不同角度的攝像頭,不同原理的激光雷達或者是3D、4D毫米波雷達,所以大家開始基于BEV去形成一個范式。
BEV加transformer的方案最厲害的點就在于給智能感知一個新范式,大家可以基于這個范式去積累更多的數據和模型。在硬件層面,可能更多給硬件一些幫助,當軟件的適配平臺化能力得到提升的時候,那么硬件的改變它給軟件帶來的障礙就沒有那么大了。
Q:BEV是不是跟著大模型訓練,BEV構造出來的數據場景是不是大模型訓練實現的基礎,或者說更方便大模型來訓練出一些輔助駕駛的模型?
A:可以把BEV梳理為三個階段:
用傳統的只知道攝像頭的內參幾何變換的方式得到的,但因為外部道路環境、車本身俯仰角的變化,使得模型很容易失效;
開始去嘗試引入到車的位置信息,道路信息,然后開始去用深度學習去做BEV;
2021年開始,特斯拉把transformer和BEV做了結合之后,增加了多傳感器,國內車廠開始跟隨此方案,第三個階段確實和大模型有非常大的關系。
Q:按目前的法律規定來說,未來 BEV構圖的語義地圖可以用到其他車上嗎?
A:這取決于一個點, BEV模型所生成的語義地圖能不能夠非常精確地重構關鍵的地理信息。如果能這個本身一定是需要被監管,如果它的程度不足以對國家造成安全傷害,但是卻又能夠幫助車輛進行城市道路下或者高速公路的NOA功能,這就是可以被保留。但是我們不太了解這個度在哪里。
現階段重構出來的如果是個局部地圖還好,但如果是把很多的車輛都放在一起,去形成一個全局地圖可能會有問題。
Q:transformer和BEV方案對最低算力要求是多少?
A:基本上是基于200Tops以上算力,保證有很好的效果,BEV模型現階段還是在比較依賴大算力的。
Q:在BEV的技術下如何兼顧遠距離,特別是大于100米的感知精度?
A:BEV里面本身已經有了transformer,已經做了很多優化了,但現在的體量模型的復雜度都還是很高的,不可能看得非常的遠。
那索性在BEV超視距的范圍內,增加一個原本傳統的算法,用2D算法去跟蹤更加遠的物體,但是當它進入到了BEV體系之后,我們可以在幾何上做變換,認為它是同一個物體。
Q:BEV方案落地后,未來對地圖的需求是不是會大幅度減少,BEV對整個技術棧有怎樣的影響?
A:如果是做地圖的同學考慮轉換專業,比如原來做定位、slam這些做定位的可能會相對容易轉過去,它的底層有很多比較像的地方。當然如果原來做規劃決策,那還是可以的。
至少從現在的技術趨勢來看,以后可能用的也許就是一個導航地圖或者ADAS地圖,或者是由眾包構建出來的語義地圖。趨勢是相對明確的,就是要輕地圖重感知。
Q:自研BEV的難度和研發周期必備的前置條件,剛才提到有大數據,那么基礎設施有哪些?
A:首先就是數據,其次是要盡快形成數據閉環,獲取數據的方式要改變,能夠通過眾包和實際生產環境里面的量產車去得到數據。
再有就是虛擬仿真,其實是因為有些場景,比如說極端場景,比如車禍場景等等這種,是沒有辦法去采集的,那么也許就需要虛擬仿真。
還要有數據中心,現在模型的復雜度在提升,多幀之間的處理,數據的量也在爆發,所以可能大的車廠后續需要有自己的數據中心進行持續的數據訓練和迭代,對數據要自動標注,數據標完之后自動結構化之后還要自動的長期可持續地迭代和訓練,才能使得基于數據驅動的這些算法越來越好。
Q:目前國外和國內關于BEV的差距大概是一個什么樣的情況?
A:在學術層面來說,非常顯性的趨勢是,一個創新性、顛覆性的技術可能不是中國人提出來的,但是我們有能力很快就follow它,把它變得更好。
但是在工程化層面,我們應該把特斯拉和其他的海外的的OEM分開,那么然后再把咱們中國的OEM放進來,在很多層面,特斯拉是顯性領先的。
整體來說, 全球化的OEM開始去要開始反思自己為什么這么慢,然后為什么在人工智能方面持續的投入不夠多等等,那么所以特斯拉是領先的,接下來可能是咱們的一些相對來說比較重投入的的OEM。
Q:怎么看待純視覺和激光雷達的路線?
A:某種意義上,激光雷達是對我們的訓練數據不足的一個補充。如果假設有無限的、準確的結構化數據,確實是不需要激光雷達,可以快速的訓練出來一個模型,這個模型因為數據量很大,可以無限接近激光雷達的精度,但因為現在我們的所得到的數據量有限,我們就想又想要得到一個不錯效果的車,那么激光雷達放進來,它就是一個好又快、顯性度高的補充。
Q:單目攝像頭本身有它的缺陷,然后目前也有一些公司去堅持要走就是雙目視覺的路線,比方說大疆,怎么看目前堅持走雙目方案的供應商?
A:我曾跟大疆的沈劭劼討論過這個話題。大疆之所以選擇雙目,是因為要去解決物體障礙物分類的問題,如果是用現在的BEV本質上無法解決這個問題,雙目確實也還是很好的補充。
另外,還可以選擇雙目加上毫米波雷達,但如果成本有限,那么可以選擇雙目或者是單目加毫米波雷達,那么在傳統系統設計里還傾向于異構,即一個單目加一個毫米波雷達,因為它是異構融合傳感器。
Q:隨著BEV發展,對于數據量的需求是一個量級的提升,那么有大量的標定數據,在不同的車型和不同的攝像頭配置方案的背景下,它能夠做到通用嗎?
A:這個問題其實是針對的是提供數據服務的提供商,然后他們怎么去更好的去服務好這些OEM。
成本會增加,難度是在變,大成本是在增加。自動標注的算法能不能夠盡量多的去取代人工,比如人工只做抽樣檢測或者做檢測,但不用再標了。也許這是一個未來的好方向,但一定需要大量的、準確的結構化信息,而且2D數據復用不了。
Q:車廠、Tier 1解決方案商和芯片公司哪一方有可能會在BEV方面做得更好?
A:大概在兩年前,判斷哪一家車廠能夠做得更好的時候,我當時總結說,哪一家車廠能夠在短時間里面得到大量的、準確的、低成本的結構化信息,誰就會做得更好。
那么在現階段來說,如果說針對BEV這個模型來說,我覺得重要點在于它要持續的有數據灌入且能持續的迭代。
那么在持續性這個層面,傳統車廠要去克服體制的原因,這個情況就是說,我們需要有會做決定的人,他知道要持續的、不斷為這個事情,為訓練數據收集數據形成數據閉環,去不斷的優化算法,這個事情要持續的迭代和升級。
首先,BEV作為算法的Tier1或Tier 2安身立命的東西,他們是有大概率做好的。第二個是以新技術作為賣點的的新造車。
來源:第一電動網
作者:HiEV
本文地址:http://m.155ck.com/kol/203477
文中圖片源自互聯網,如有侵權請聯系admin#d1ev.com(#替換成@)刪除。




先估價再買車,買的放心開的安心
您的詢價信息
已經成功提交我們稍后會聯系您進行報價!







 京公網安備
11010502033163號
京公網安備
11010502033163號