國(guó)產(chǎn),存算一體,基于 12nm 工藝制程,在 Int8 數(shù)據(jù)精度下實(shí)現(xiàn)高達(dá) 256TOPS 的物理算力,典型功耗低至 35W,能效比高達(dá) 7.3Tops/W,高計(jì)算效率、低計(jì)算延時(shí)、低工藝依賴……
這是5月10日 ,后摩智能正式發(fā)布的首款存算一體智駕芯片鴻途?H30的關(guān)鍵參數(shù),是不是讓你眼前一亮?

△后摩智能創(chuàng)始人兼CEO吳強(qiáng)
這款芯片的關(guān)鍵詞有兩個(gè)——“存算一體”和“智駕”。
后者并不陌生,且已有特斯拉FSD、英偉達(dá)Orin、地平線征程5等代表產(chǎn)品。因此,想要在這些產(chǎn)品中留下印象,“存算一體”是關(guān)鍵。
1
—
什么是存算一體?
存算一體這個(gè)概念最早可以追溯到上個(gè)世紀(jì),沒有很快興起主要有兩個(gè)原因:
一是當(dāng)時(shí)存算一體雖然可以解決部分性能提升問題,但能解決的部分在整個(gè)系統(tǒng)中只占10%-20%,意義不大。更重要的一點(diǎn)是,過去幾十年摩爾定律還在持續(xù)被驗(yàn)證,行業(yè)并不需要架構(gòu)的創(chuàng)新,只需要每一到兩年升級(jí)一代芯片工藝,就能實(shí)現(xiàn)性能的快速提升和成本的同步降低。
但隨著摩爾定律逐漸走到盡頭,以及近幾年云計(jì)算和人工智能應(yīng)用的快速發(fā)展,數(shù)據(jù)洪流撲面而來,數(shù)據(jù)搬運(yùn)慢、搬運(yùn)能耗大等問題成為了計(jì)算的關(guān)鍵瓶頸。

△馮諾依曼架構(gòu)示意圖
在經(jīng)典的馮諾依曼架構(gòu)中,數(shù)據(jù)存儲(chǔ)與數(shù)據(jù)處理在物理上是兩個(gè)相互分離的單元,在數(shù)據(jù)處理過程中,處理器與存儲(chǔ)器之間需要不斷地通過數(shù)據(jù)總線交換數(shù)據(jù)。
從下圖不難看出,算力發(fā)展速度遠(yuǎn)超存儲(chǔ)器,導(dǎo)致存儲(chǔ)器的數(shù)據(jù)訪問速度愈發(fā)跟不上處理器的數(shù)據(jù)處理速度,后者性能與效率受到嚴(yán)重制約,這就是我們常說的“存儲(chǔ)墻”。
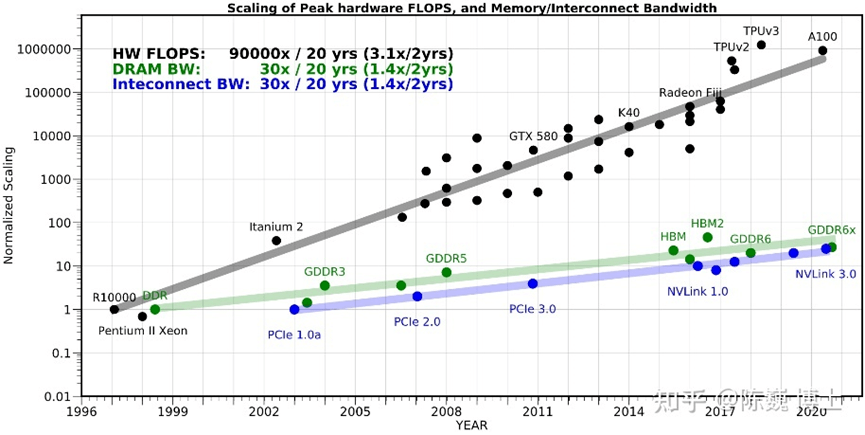
△截圖來自《存算一體芯片技術(shù)及其最新發(fā)展趨勢(shì)》
另外,從處理單元外的存儲(chǔ)器提取數(shù)據(jù),搬運(yùn)時(shí)間往往是運(yùn)算時(shí)間的成百上千倍,整個(gè)過程的無用能耗大概在60%-90%之間,能效非常低。“功耗墻”,同樣成為了限制芯片發(fā)展的因素。
解決數(shù)據(jù)在計(jì)算單元和存儲(chǔ)單元之間頻繁的移動(dòng)問題,成了深度學(xué)習(xí)加速的最大挑戰(zhàn)。
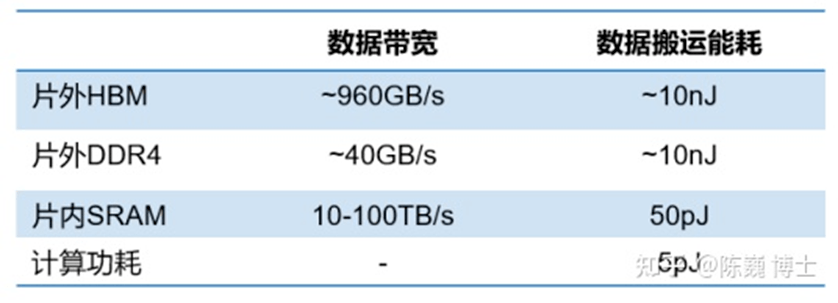
過去幾年,行業(yè)嘗試了多種方法,例如為了減少數(shù)據(jù)搬運(yùn)的大粒度的指令(集)或?qū)S弥噶?/span>(集)、訪存優(yōu)化(替換/預(yù)取)、調(diào)度優(yōu)化、內(nèi)存/緩存壓縮、低擺幅電路、大緩存技術(shù)等;或是提高并行度的SIMD、SIMT、STMD、指令預(yù)測(cè)等技術(shù);還有降低數(shù)據(jù)進(jìn)度、使用新型封裝、器材或材料等方式,但都未能從根本上解決數(shù)據(jù)密集型算力的問題。
突破兩堵墻,依然是關(guān)鍵,此時(shí),存算一體架構(gòu)開始重入行業(yè)視野。
2
—
以場(chǎng)景做選擇
存算一體可以簡(jiǎn)單從字面理解為在存儲(chǔ)單元中潛入計(jì)算能力,以新的運(yùn)算架構(gòu)進(jìn)行二維和三維矩陣乘法/加法運(yùn)算,從本質(zhì)上消除不必要的數(shù)據(jù)搬移的延遲和功耗,大幅提高AI計(jì)算效率,降低成本。
從實(shí)現(xiàn)路徑上,雖然沒有統(tǒng)一的定義,但根據(jù)計(jì)算單元與存儲(chǔ)單元的關(guān)系主要有查存計(jì)算、近存計(jì)算、存內(nèi)計(jì)算和存內(nèi)邏輯,而目前行業(yè)中使用最多的是近存計(jì)算和存內(nèi)計(jì)算。
前者計(jì)算操作由位于存儲(chǔ)區(qū)域外部的獨(dú)立計(jì)算芯片/模塊完成,通過先進(jìn)的封裝方式以及合理的硬件布局和結(jié)構(gòu)優(yōu)化,增強(qiáng)二者間通信帶寬,增大數(shù)據(jù)傳輸速率,進(jìn)而提高數(shù)據(jù)處理效率。這種架構(gòu)設(shè)計(jì)的代際設(shè)計(jì)成本較低,適合傳統(tǒng)架構(gòu)芯片轉(zhuǎn)入。典型代表是AMD的Zen系列CPU,2021年年末,阿里達(dá)摩院推出基于SeDRAM的3D堆疊芯片也是采用了該技術(shù)路徑。
而存內(nèi)計(jì)算由位于存儲(chǔ)芯片/區(qū)域內(nèi)部的獨(dú)立計(jì)算單元完成,存儲(chǔ)和計(jì)算可以是模擬也可以是數(shù)字。
國(guó)外的Mythic,千芯、閃億、知存以及這次發(fā)布新產(chǎn)品的后摩智能都是這條路徑上的代表企業(yè)。
除了技術(shù)路徑,在存儲(chǔ)器選擇上,存算一體芯片也有兩個(gè)主要方向:
一、易失性存儲(chǔ)器,但在計(jì)算上具有突出的優(yōu)勢(shì)的,主要有SRAM靜態(tài)隨機(jī)存儲(chǔ)器和DRAM動(dòng)態(tài)隨機(jī)存儲(chǔ)器;
二、非易失存儲(chǔ)器,在芯片的成本上具有一定優(yōu)勢(shì)的,主要有RRAM 阻變隨機(jī)存儲(chǔ)器、MRAM 磁性隨機(jī)存儲(chǔ)器、FeRAM 鐵電隨機(jī)存儲(chǔ)器、PCM 相變存儲(chǔ)器、FLASH 閃存等。
世上沒有完美的選擇,自然沒有一種存儲(chǔ)器具備在所有場(chǎng)景下的絕對(duì)優(yōu)勢(shì)。因此,芯片企業(yè)存儲(chǔ)器件的選擇,以及數(shù)字存算還是模擬存算的選擇,都與應(yīng)用場(chǎng)景密切相關(guān)。
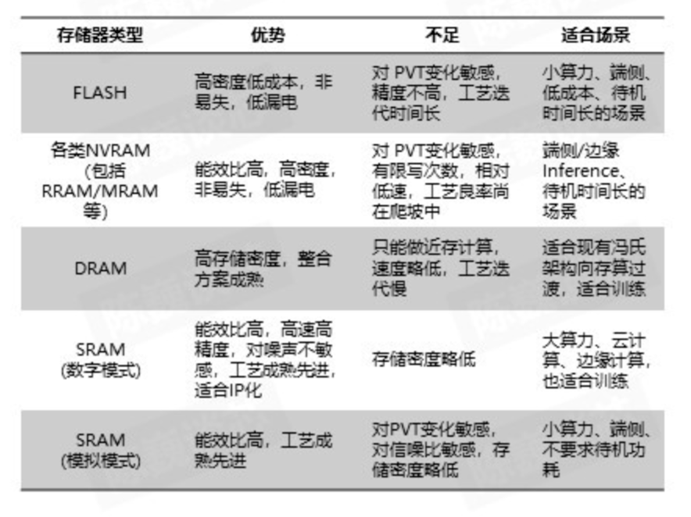
△截圖來自《存算一體芯片技術(shù)及其最新發(fā)展趨勢(shì)》
對(duì)于把重點(diǎn)放在智駕的后摩,SRAM顯然是其最優(yōu)解。
3
—
以新型架構(gòu)擴(kuò)展算力
根據(jù)后摩智能聯(lián)合創(chuàng)始人兼研發(fā)副總裁陳亮介紹,后摩面向智能駕駛場(chǎng)景打造了專用 IPU(處理器架構(gòu))——天樞架構(gòu),采用多核、多硬件線程的方式擴(kuò)展算力。
一個(gè)芯片里有4個(gè)完全相同的IPU核,每個(gè)IPU核內(nèi)部,又由4個(gè)完全相同的Tile組成,每個(gè)Tile對(duì)應(yīng)一個(gè)或者多個(gè)硬件線程,每個(gè)Tile的內(nèi)部又包括了CPU、Tensor Engine、Special Function Unit, DMA和Vector Processor等,其中Tensor Engine就是由存算電路和一個(gè)Feature Buffer,還有相應(yīng)的一些控制電路組成,這些計(jì)算單元在CPU的統(tǒng)一調(diào)度下進(jìn)行計(jì)算。
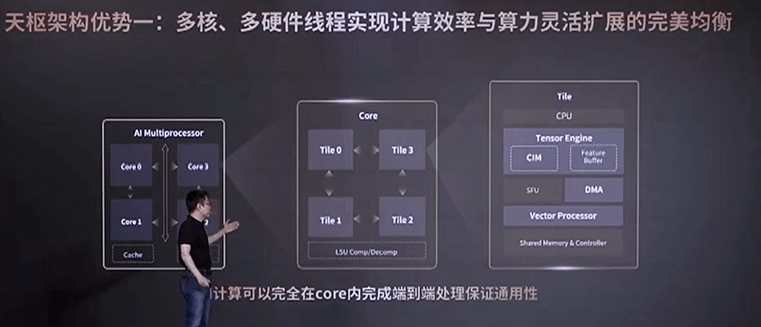
“在SRAM電路旁邊,我們加入了一些定制化的電路結(jié)構(gòu),包括乘法器、加法數(shù)、累加器等,這些定制化的電路結(jié)構(gòu)和SRAM的電路整合在一起,就實(shí)現(xiàn)高效的存內(nèi)并行計(jì)算。存儲(chǔ)器單元中存儲(chǔ)的數(shù)據(jù),可以在同一時(shí)刻一起讀出來參與計(jì)算。” 陳亮解釋說,“定制化的乘加電路和傳統(tǒng)的SRAM Bit Cell電路完全融合在一起,帶來更加規(guī)整的電路結(jié)構(gòu),因而就有更緊湊的電路設(shè)計(jì),面積也就相應(yīng)減少了。不管是傳統(tǒng)的SRAM電路,還是定制化的計(jì)算電路,都是純數(shù)字的設(shè)計(jì),因而不會(huì)有任何的計(jì)算誤差。”
現(xiàn)場(chǎng),陳亮還展示了后摩智能存算一體電路的一些技術(shù)參數(shù)與業(yè)界5nm工藝的對(duì)比。后摩這款芯片在采用相對(duì)更成熟的12納米制程后,按陳亮的說法,實(shí)現(xiàn)了“既要馬兒跑,又讓馬兒少吃草”的結(jié)果。
“我們已經(jīng)在28納米、22納米、16納米、12納米等不同工藝下進(jìn)行過流片和測(cè)試。”

△后摩智能聯(lián)合創(chuàng)始人兼研發(fā)副總裁陳亮
據(jù)悉,目前鴻途?H30 已成功運(yùn)行常用的經(jīng)典CV網(wǎng)絡(luò)和多種自動(dòng)駕駛先進(jìn)網(wǎng)絡(luò),包括當(dāng)前業(yè)內(nèi)最受關(guān)注的 BEV 網(wǎng)絡(luò)模型以及廣泛應(yīng)用于高階輔助駕駛領(lǐng)域的 Pointpillar 網(wǎng)絡(luò)模型。以鴻途?H30 打造的智能駕駛解決方案已經(jīng)在新石器的無人小車上完成部署,這也是業(yè)界第一次基于存算一體架構(gòu)的芯片成功運(yùn)行端到端的智能駕駛技術(shù)棧。
4
—
量產(chǎn),漫長(zhǎng)的季節(jié)
本次發(fā)布會(huì),后摩智能同步推出了基于鴻途?H30 芯片打造的智能駕駛硬件平臺(tái)——力馭?,CPU 算力高達(dá)200 Kdmips,AI算力達(dá)256Tops(INT8物理算力),支持多傳感器輸入。官方介紹,力馭?平臺(tái)功耗僅為 85W,可采用更加靈活的散熱方式,實(shí)現(xiàn)更低成本的便捷部署,有利于推動(dòng)大算力智能駕駛場(chǎng)景的普及應(yīng)用。
此外,為了讓客戶擁有更好的產(chǎn)品使用體驗(yàn),后摩智能還基于鴻途?H30 芯片自主研發(fā)了一款軟件開發(fā)工具鏈——后摩大道?,支持 PyTorch、TensorFlow 、ONNX 等主流開源框架,編程兼容 CUDA 前端語法,同時(shí)支持 SIMD 和 SIMT 兩種編程模型,兼顧運(yùn)行效率和開發(fā)效率,以無侵入式的底層架構(gòu)創(chuàng)新保障了通用性的同時(shí),進(jìn)一步實(shí)現(xiàn)了鴻途?H30 的高效、易用。
據(jù)后摩智能聯(lián)合創(chuàng)始人兼產(chǎn)品副總裁信曉旭透露,鴻途?H30 將于6月份開始給 Alpha 客戶送測(cè)。同時(shí),后摩智能的第二代產(chǎn)品鴻途?H50 已經(jīng)在全力研發(fā)中,將于2024年推出,支持客戶 2025年的量產(chǎn)車型。

△后摩智能聯(lián)合創(chuàng)始人兼產(chǎn)品副總裁信曉旭
行業(yè)對(duì)大算力芯片需求的激增,給了后來者后摩智能迎頭趕上的空間,不到半年時(shí)間完成芯片流片、點(diǎn)亮到發(fā)布,后摩對(duì)于時(shí)代給予的機(jī)會(huì)展現(xiàn)出了十分積極的姿態(tài)。不過這還僅僅是開始,想要進(jìn)汽車供應(yīng)鏈,產(chǎn)品送測(cè)后還有定點(diǎn)、訂單、小規(guī)模試裝,然后才是規(guī)模量產(chǎn),量產(chǎn)后還要看終端的銷量……過程中的變數(shù)依然很大。
另一個(gè)重大課題,就是讓每一家科技公司都頭痛的工程交付。就像發(fā)布會(huì)現(xiàn)場(chǎng)一位下游需求方說的,“存算一體是個(gè)新的方向和嘗試,但關(guān)鍵要看量產(chǎn)落地的能力。”
對(duì)于后摩,依然有一個(gè)“漫長(zhǎng)的季節(jié)”,度過之后,將是另一片天地。
來源:第一電動(dòng)網(wǎng)
作者:智車星球
本文地址:http://m.155ck.com/kol/202412
文中圖片源自互聯(lián)網(wǎng),如有侵權(quán)請(qǐng)聯(lián)系admin#d1ev.com(#替換成@)刪除。




先估價(jià)再買車,買的放心開的安心
您的詢價(jià)信息
已經(jīng)成功提交我們稍后會(huì)聯(lián)系您進(jìn)行報(bào)價(jià)!

網(wǎng)大牛說專欄作者")






 京公網(wǎng)安備
11010502033163號(hào)
京公網(wǎng)安備
11010502033163號(hào)