“我們團隊目前最重要的工作就是復現Sora”,清華大學助理教授劍寒(化名)告訴「智車星球」,他的主要研究方向是機器人相關的計算機視覺,“不止我們,從2月16日(Sora發布當天)開始,基本所有在這個賽道的人都在轉方向。”
關于原子彈,最有價值的情報就是它可以被造出來。
這句話再次被Sora印證。
不過在劍寒看來,這很正常,“科研界可能有100種前瞻方向,不可能都嘗試,OpenAI出來的效果這么好,大家開始學習他的做法,這沒有什么問題。就像世界上有這么多材料,嘗試到用鎢做燈絲呈現出了很好的效果,大家都會跟進。”
除了技術端,資本端的跟進也很迅速。
券商的朋友甚至等不及春節假期結束就找到我,詢問是否能介紹相關專家交流一下Sora對自動駕駛的影響。
這場關于“大模型+自動駕駛”能否產生新的化學反應的討論,再次因為OpenAI帶來了新一輪的熱度。
1
—
新的仿真路線
此次Sora的推出,展示出了明顯優于此前生成式視覺模型的成果,這也讓不少人對其在自動駕駛仿真領域的應用產生了期待。

△知名連續創業者Gabor Cselle在測試關于美麗東京白雪皚皚的提示詞后,得出的結論是Sora在長鏡頭上表現得更好。
在51Sim CEO鮑世強看來,Sora 已經展現出了多視角長時長下一致性較高的圖像,場景的真實度和細節也很好。
“其實從仿真的角度看,生成式視頻模型做的事和游戲引擎沒有本質區別,只是一個是更可控的顯式的,一個是數據驅動的隱式的。游戲引擎的一個劣勢是如果要達到較強的真實感門檻較高,需要建模大量的高質量資產,優點是可控制性和可編輯性較強,世界完全受控。但 Sora的可編輯性以及可控性從目前的展示來看還不確認,我認為挑戰還是比較大。” 鮑世強解釋道。“
目前,合成數據主要分為三個路線——物理仿真與圖形渲染路線、基于神經輻射場(NeRF、3DGaussion 等)的場景重建路線以及基于世界模型的生成路線。

“基于世界模型的生成路線還處于發展的早期階段,與視頻創作領域不同,智駕場景落地確定性要求比較高,需要呈現出一致性和物理規律,如何可控的生成更多有價值的Corner Case 還有待深入探討,但后續發展空間是巨大的。“ 鮑世強告訴[智車星球]。
目前,在這條垂直賽道上,國內已經有企業在做相關研究。
去年9月,極佳科技和清華大學的研究人員就推出了真實世界驅動的自動駕駛世界模型DriveDreamer。
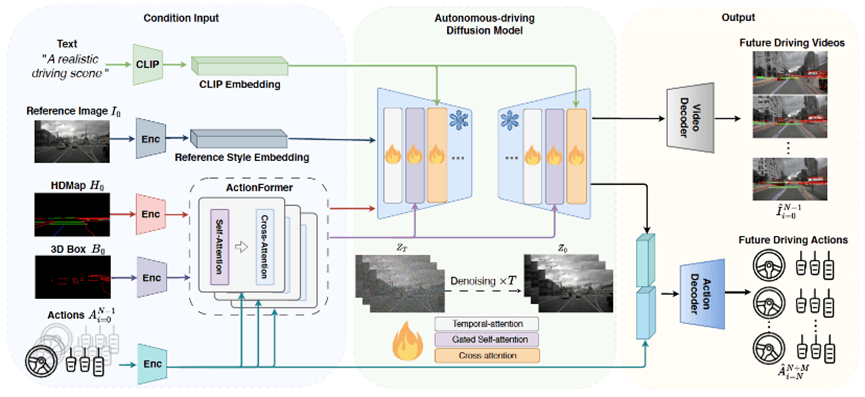
△DriveDreamer 總體結構框圖
據極佳科技CEO黃冠介紹,DriveDreamer使用了數十億圖像數據預訓練的 Diffusion model 作為基礎模型,并利用百萬張自動駕駛場景圖像幀進行模型訓練,在此過程中引入了數十億可學習參數。
DriveDreamer能夠生成符合交通結構化信息的視頻;可以根據文本描述改變生成視頻的天氣、時間等;可以根據輸入的駕駛動作生成不同的未來駕駛場景視頻。
“現在已經有不少客戶基于DriveDreamer做數據生成、閉環仿真,Sora的出現也讓我們對這個方向更確定。當然,目前還有準確性、精細度等各方面的工程問題需要繼續提升。” 黃冠解釋道。
2
—
大模型“加速”自動駕駛
雖然文本視頻生成大模型完全進入自動駕駛量產環節還有不少需要提升的地方,但大模型對于自動駕駛是否有加成,在業內人士看來是一個需要做質疑的討論。
“在過去一年多的時間內,這已經是被廣泛驗證的事情。”長城汽車AI Lab負責人楊繼峰告訴「智車星球」,“大模型在自動駕駛領域,首先被證實效果的領域是數據重建,基于此誕生了新的場景生成在仿真領域的機會;Sora無疑規模更大也更通用,但是在自動駕駛領域的落地還需要進一步探索,特別是針對空間和語音應用。然后影響到的end to end,以及最近很熱的LLM-based driving agent類型的大模型算法架構。”
簡單來說,就是通過增加推理能力來處理復雜場景從而提高性能,并通過極大地簡化模型開發來降低成本。
自動駕駛軟件的初創公司Ghost Autonomy(曾獲得OpenAI創業基金500萬美元投資,旨在將大規模、多模態的大語言模型引入自動駕駛領域)的模型工程師Prannay Khosla也在文章《One Model To Rule The Road?》中提到,大語言模型(LLMs,廣義上被稱為基礎模型)正在改變自動駕駛開發的多個環節。
首先是在理解及標注數據層面,Prannay Khosla提到模型工程的核心是數據問題,即更好的數據產生更好的模型,“更好的數據”不僅僅是關于規模,還有完備性。訓練集必須代表現實世界中可能遇到的每一個概念,例如,每一種車道標記類型、每一種道路配置、每一種障礙物、建筑類型等。收集所有這些數據不僅昂貴,而且還需要進行復雜的數據挖掘,從而標注相關樣本以開發出完備的訓練集。人類需要數十萬小時來開發這些訓練集,但是它們仍然不完備。
而大型模型在解決這個問題上已被證明特別有用,能夠通過語言接口對復雜問題進行zero-shot泛化(即解決從未在相關數據集上訓練過的新任務),以更低的代價對數據集進行整理和標注。在這種應用中,大型模型可能不用于最終產品的推理,但用于幫助訓練最終交付的模型。
其次,大模型能提升可解釋性。早期的自動駕駛被龐大的代碼庫所主導,導致在復雜場景中難以進行調試。LLMs提供了一種與神經網絡中的注意力層進行交互的新途徑,使得在駕駛系統內部實現提示和可解釋性成為可能。同樣,這里的大型模型是一個工具,幫助開發和解釋在運行時部署的其他模型。
而隨著LLMs顯示出可以真正“理解世界”的潛力,Prannay Khosla認為這種新的理解水平可以擴展到駕駛任務,使模型無需顯式訓練(Explicit Training),就能安全自然地駕馭復雜場景,這為解決“長尾問題”提供了新的路徑。LLMs還顯示出在決策中使用大量上下文信息的能力。
最后,Prannay Khosla也提到了基于action的生成式視覺模型,例如GANs和Diffusion models,可以在線創建逼真的駕駛場景,可以用于有效的仿真。
但同樣,Prannay Khosla也提到尚不完全清楚大型視覺模型是否能生成有意思的Corner Case場景。像素級仿真渲染對于構建規劃器和測試道路預測模型非常有用,但對于測試和制造自動駕駛汽車所需的規模來說,計算效率可能不高。
3
—
自動駕駛終局在哪?
目前,視頻生成方法主要分為兩類:基于Transformer和基于擴散模型。
前者源于大型語言模型方案,通常是采用對下一個Token的自回歸預測或對masked Token的并行解碼來生成視頻。
利用Transformer進行Token預測可以高效學習到視頻信號的動態信息,并可以復用大語言模型領域的經驗,因此,基于Transformer的方案是學習通用世界模型的一種有效途徑。
擴散模型是近兩年來視頻生成領域的研究熱點,是“文生圖”的代表,相關研究成果也有不少。比如在2D擴散模型潛在空間的基礎上引入時間維度,并使用視頻數據進行微調,有效地將圖像生成器轉變為視頻生成器,實現高分辨率視頻合成;有基于預訓練的2D擴散模型構建了級聯視頻擴散模型;也有基于Transformer的擴散模型改進了視頻生成。
不過,基于擴散模型的方法難以在單一模型內整合多種模態。此外,基于擴散模型的方案難以拓展到更大參數,因此很難學習到通用世界的變化和運動規律。
Sora則是結合了Transformer 和 Diffusion 兩個模型,在過去DALL.E和GPT的研究基礎上,采用了DALL.E 3中的重述技術。因此能更好遵循用戶的文本描述,并且有極強的擴展性。
再簡單些,OpenAI用GPT的能力做視頻文本對齊,通過將多個高分辨率視頻素材進行降維處理,然后密集訓練,最后就是我們熟悉的大力出奇跡。
陽光底下無新鮮事,雖然沒有網絡大小、用了哪些數據、具體怎么訓練等細節,但從OpenAI公布的報告中,并沒有“武功秘籍”般的存在,思路和方法都是大家熟悉的東西。
但AI熱與明星公司OpenAI的結合,再加上關于技術本身之外的討論,讓Sora的熱度來到了極高的位置,也引出了大家對自動駕駛終局的討論。
2月18日,馬斯克在科技主播 @Dr.KnowItAll 一條主題為“OpenAI 的重磅炸彈證實了特斯拉的理論”的視頻下留言,表示“特斯拉已經能夠用精確物理原理制作真實世界視頻大約一年了”。
隨后馬斯克在 X 上轉發了一條 2023 年的視頻,內容是特斯拉自動駕駛總監 Ashok Elluswamy 向外界介紹特斯拉如何用 AI 模擬真實世界駕駛。
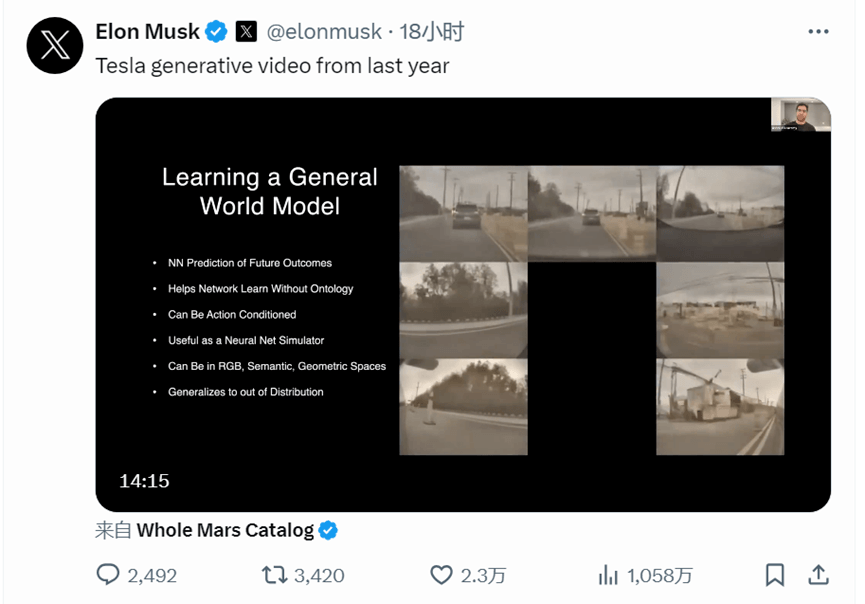
訓練 AI 理解和生成一個真實的場景或世界,是特斯拉與Sora一致的訓練思路。
過去十幾年,雖然技術在不斷迭代,但自動駕駛的本質依然是通過海量數據教會系統開車,即便目前在不少環節已經有大模型加入,也只是加速了過程,并沒有解決自動駕駛研發過程中遇見的問題。
“但是自動駕駛從世界感知進入到通用認知以后,自動駕駛的本質很可能就會發生變化,那就是Al Agent——LLM+Memory+Tool+Planning。自動駕駛就變成了怎么教一個通用智慧體開車的問題,通過大模型的預訓練去學會推理、記憶等能力和道路駕駛等通用知識,通過SFT去強化場景駕駛行為,通過RL把數據閉環變成獎勵模型。這跟當前依賴海量數據和Corner Case的思路完全不同。” 楊繼峰說道。
“(自動駕駛)最終可能就是一個語言模型加世界模型。”黃冠也提出了類似觀點。
可以說,對于自動駕駛,Sora這次的小試牛刀,不僅展示出了相關技術在自動駕駛仿真領域的應用潛力,更是讓行業看到大模型對真實世界有了理解和模擬之后,引發了對于自動駕駛發展方向的思考。
這場AI熱給自動駕駛帶來的新課題,已然擺在眼前。
來源:第一電動網
作者:智車星球
本文地址:http://m.155ck.com/kol/220096
文中圖片源自互聯網,如有侵權請聯系admin#d1ev.com(#替換成@)刪除。




先估價再買車,買的放心開的安心
您的詢價信息
已經成功提交我們稍后會聯系您進行報價!








 京公網安備
11010502033163號
京公網安備
11010502033163號